Tuesday, 10 August, 2021
Development Diary #6
 Jon Pither
Jon Pither Welcome to XTDB Development Diary #6. Throughout the six months since the last diary entry we’ve been at hard at work: adding new features, making XTDB faster, and working on ambitious plans for the future. Join us as we take a walk through the last half-year of XTDB development.
Performance
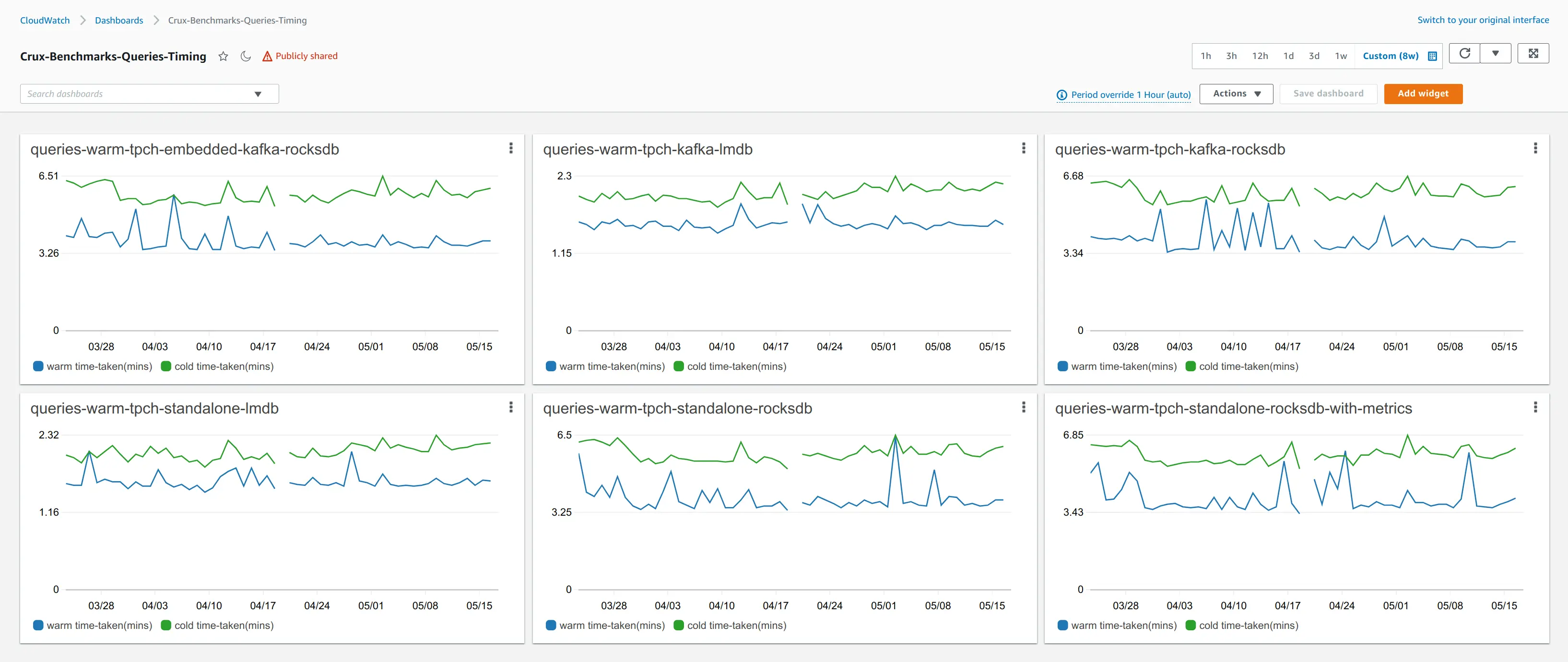
Since the earliest days of development, all "hot path" engineering work has progressed carefully.
We exercise XTDB with an extensive home-grown unit test suite in tandem with industry benchmarking suites that are adopted into the xtdb-bench project.
Jeremy Taylor has written up our approach to query performance benchmarking, which discusses the TPC-H benchmark suite, the University of Waterloo’s WatDiv suite, and more.
These benchmarks have been valuable for ensuring that the join order heuristics in the query planner are kept sufficiently general. It is because of this query planner that XTDB is able to support truly declarative Datalog, which means that users don’t need to concern themselves with manually tuning clause ordering to achieve good performance. Once a query has been submitted to XTDB, the planner will rewrite the join-order as it sees fit based on index statistics that evolve alongside the data.
To help XTDB make the best decisions when it chooses the all-important join order, we have recently added HyperLogLog (HLL), which succinctly records the approximate amount of distinct values in a large set. In particular, HLL records the distribution of values correlated to a given attribute. We have validated the index upgrade in the wild with our clients and observed circumstances where the use of HLL dramactically increases query speed for certain types of complex queries. The use of HLL is an internal change, so users don’t need to change anything in their queries or code to take advantage of it.
Egeria
[The XTDB Connector is] currently the highest-performance open source persistent repository for Egeria across all operations: read, write, update, search, and purge.
Project Egeria Maintainer
Outside of our own performance work, the team working on the Linux Foundation’s Egeria project for "Open Metadata and Governance" has been analysing XTDB as a successor to JanusGraph as the default graph storage layer with the added benefit of supporting temporal metadata queries. The majority of the work on the Egeria Crux Connector (hopefully to be renamed "Egeria XTDB Connector" soon) is already complete, and the performance assessment of XTDB is very favourable:
In almost all cases, the XTDB repository is significantly faster than JanusGraph […] with very little variability […] even at 8 times the volume of metadata.
Once the connector becomes generally available, efficient temporal graph queries will further differentiate Egeria as the leading option for enterprises in need of an Open Metadata solution.
Lucene & Full-Text Search
The Lucene module released with XTDB 1.13 (still named "Crux" at the time) in December 2020 has been well received by our clients and other early adopters. The functionality allows users to quickly perform full-text searches for string-value attributes.
The module provides a simple
text-search
predicate function.
For example: (text-search :name "Iva*") will find entities containing the "Iva" prefix anywhere in the tokenized string value under the :name attribute across all entites in the database.
Since XTDB is a document database, we’ve also provided another predicate function lucene-text-search that takes a Lucene query string, and allows for querying across fields.
For example: (lucene-text-search "surname: Smith AND firstname: Ivan").
However, if users want to further configure the xtdb-lucene integration, the options have, until recently, been quite limited:
-
Register your own predicate function, for example, an OR expression.
-
Supply your own document indexer, for example the multi-field extension.
-
Since XTDB is open-source, you can always fork the Lucene module for your own requirements. But that comes with a higher maintenance burden than we expect our users to shoulder.
To offer an alternative to the complexity involved in those options, we released XTDB 1.18 in July with a completely overhauled Lucene integration. The 1.18 Lucene module retains the existing Datalog predicate functions and indexing options but also opens up new extension points for users.
Specifically, users can now query Lucene directly using the xtdb.lucene/search API which returns a lazy iterator (without temporal filtering or other Datalog integration).
Multiple Lucene stores can now be configured as secondary indexes with independent configuration and checkpointing.
These new extension points have already simplified the Egeria team’s work on their advanced Lucene search requirements.
Bug Fixes
We’ve fixed a number of bugs that have been reported to us. Please have scan through the recent XTDB releases to see if the fixes benefit you.
We have also documented our Break Versioning methodology (credit to Peter Taoussanis).
Query Enhancements
Features like
return maps
(keyed by :keys, :syms or :strs), which reduce boilerplate code for dealing with tuples, and pull (previously eql/project)
have been added to help new users onboard from familiar systems.
Off the back of the JSON-over-HTTP changes mentioned in the last dev diary, we have also added HTTP/2 support to help with latency and throughput for large volumes of small queries and other requests. Note we also publish a Swagger page and an auto-generated OpenAPI spec. You can always find them from the HTTP module docs.
We also released a Java NIO FileSystem implemention of the DocumentStore protocol.
This means that XTDB can now use any Java NIO-compatible file store.
For example,
Google Cloud Storage
can now be used to host documents and checkpoints without Google-specific integration code.
Users should have an easier time scaling queries across multiple nodes on Google Cloud.
Case Studies
XTDB is used in a wide range of domains and new users often ask us for examples of XTDB in production. In May we released a "Solutions" page, listing the various applications of XTDB in the real world. From risk systems to blockchains and temporal metadata to IoT authorization, we’re happy to provide any of the written (PDF) case studies on request.
Reaching a wider audience
Maven Central
In the spirit of lowering the barrier to new JVM users, we migrated XTDB over to Maven Central in June with XTDB 1.17.1 to allow non-Clojure users to build on top of XTDB more easily. James Henderson wrote up a very detailed blog post (How-to: Clojure libraries on Maven Central) to help pave the way for other teams and projects considering a similar migration.
Java
The Java API for submitting transactions became much more IDE-friendly in XTDB 1.15. Java users can now easily construct transactions programmatically and, generally speaking, we’ve replaced usages of Clojure keyword-based maps and lists in the Java API with more strongly typed objects.
Kotlin
Building on top of the new Java API, Alistair O’Neill has released xtdb-kotlin-dsl, an idiomatic Kotlin API for querying XTDB which compiles to EDN Datalog.
He also wrote a small
billing demo
webservice.
Luminus
James Simpson has written a guide to building XTDB apps using Luminus. Luminus is a batteries-included set of customizable project templates, for the Clojure community. This allows users to get going quickly, building Clojure applications using XTDB as the back-end.
New Modules
XTDB + Corda
The XTDB team has officially released an alpha of
xtdb-corda,
a library which augments the Corda blockchain with XTDB Datalog query capabilities.
Using this module, verified Corda transactions are automatically piped into an XTDB node for seamless bitemporal graph queries.
Remy Rojas recently wrote about the module in Bridging the Blockchain / Database Divide.
XTDB + GeoJSON
In the community, a Clojure team at Teknql have put together
crux-geo
("Crux" is the old name for XTDB and hopefully this will be renamed xtdb-geo soon),
a secondary index for XTDB that automatically indexes values that conform to a GeoJSON-inspired spec.
This allows users to, for example, discover intersecting geometries.
Whilst the module hasn’t yet caught up with the newer secondary index integration points discussed above,
it is being planned.
In the meantime you can test it out with 1.17.1.
New Resources
A Virtual Tour of XTDB
The Clojure-Provo folks were gracious enough to host us for their March meetup. Jeremy gave a Virtual Tour of XTDB (neé Crüx), in which he demonstrates some complex graph query capabilities with the XTDB query engine:
(Because of the immutable nature of YouTube videos, you’ll note XTDB is still referred to as "Crux" in the video and the title.)
Clojure-Datalog Database Matrix
Back in April, the XTDB team put together a comparative matrix of open source Clojure-Datalog databases at clojurelog.github.io.
A number of Clojure developers told us that they found this matrix very helpful, since there weren’t any good summaries available previously. The matrix provides a high-level overview of each database and a feature-by-feature comparison of each:
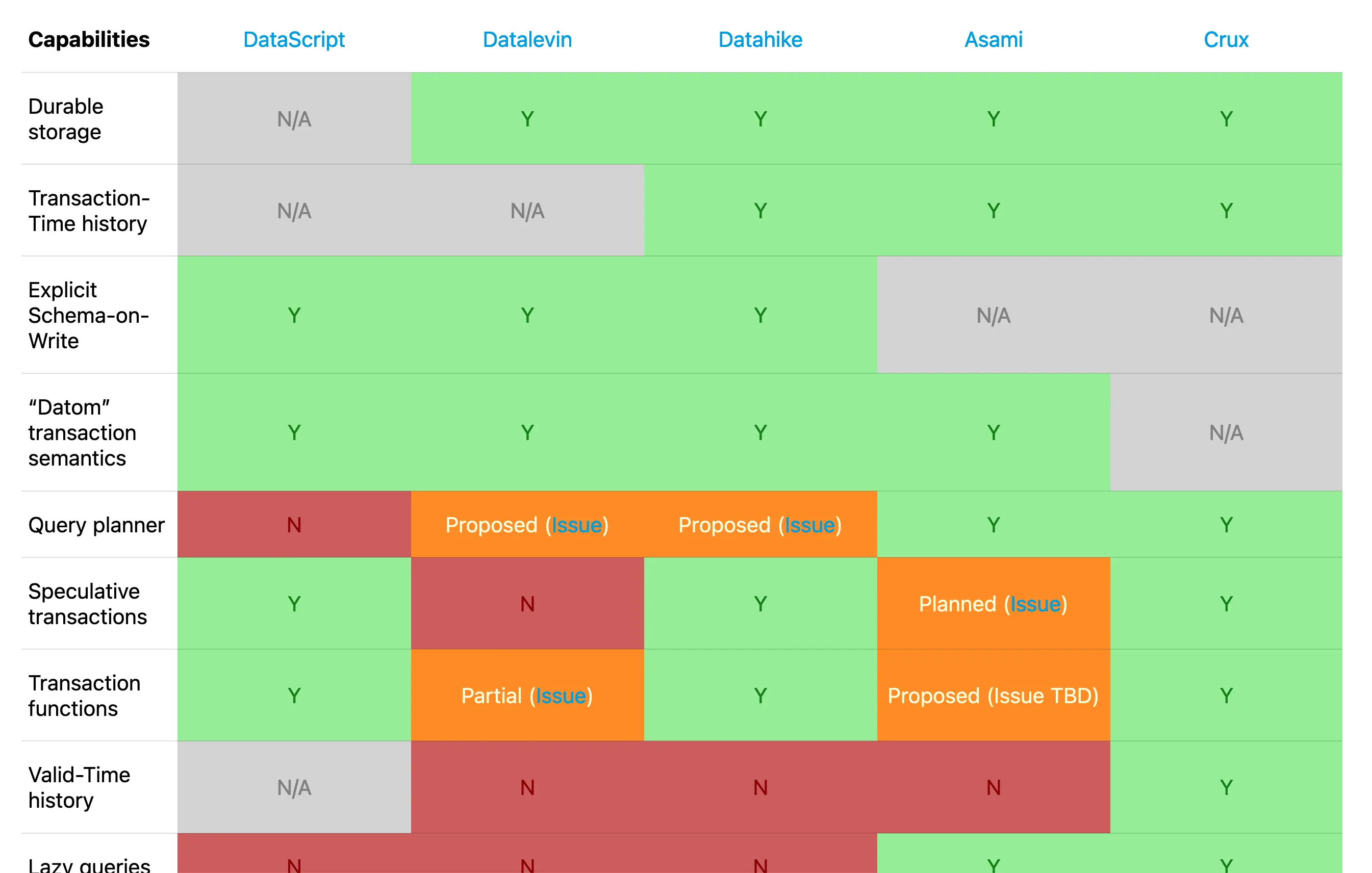
The matrix is a living document and the community is happy to incorporate changes and corrections in the GitHub repo.
Learn XTDB Datalog Today
We recently released an XTDB-flavoured version of Jonas Enlund’s classic Learn Datalog Today tutorial. You can now Learn XTDB Datalog Today live on the interactive Nextjournal platform (which is also built on Clojure!). Releasing the Learn XTDB Datalog Today GitHub repo also gave us a chance to do the same for our original "Space Adventure" tutorial, which you’ll now find in its own GitHub repo. Issues, requests, and PRs are welcome!
On the heals of the Learn XTDB Datalog Today release, the Los Angeles Clojure User Group held a collaborative learning session where they worked through the tutorial together. They have released a recording of that session on YouTube:
(Because of the immutable nature of YouTube videos, you’ll note XTDB is still referred to as "Crux" in the video and the title.)
Future
Over the last six months, behind the scenes, we have also been working intensively on adding new fundamental capabilities to XTDB. Most significantly, this includes making use of Apache Arrow in order to decouple XTDB from the existing index foundation of embedded KV storage. Whilst embedded KV storage backends like RocksDB and LMDB are great at what they do, they constrain individual XTDB nodes to holding all of the data locally. In the new model, indexed columnar chunks will be stored in a remote object store and then pulled down on-demand by nodes. This means that a given XTDB node will only store the minimal raw dataset locally that it needs to in order to answer the queries at hand.
We will be making this foundational change in a way that makes typical queries in XTDB faster still, benefitting from the cache-efficient nature of a columnar memory layout.
Alongside this change, we are building more sophisticated temporal functionality into XTDB.
Right now, XTDB provides a powerful as-of feature for querying against a particular Valid Time (otherwise known as "business time" or "application time").
We want to go much further than this, and allow XTDB users to query across time, to answer questions such as "when was this fact valid?".
For example, the new temporal query engine can answer questions like "when did Alistair join JUXT?" This means users can query documents across time without embedding and querying against specific hand-rolled time fields. Beyond this, XTDB will be able to handle temporal joins. Temporal joins enable the query engine to answer questions like "in what time period did Håkan, Steven, and Jon all work for ThoughtWorks?".
Over the next six months we will be talking a lot more about this significant upgrade to XTDB. Stay tuned!
Get in touch
Please do take XTDB for a spin and, as always, do get in touch with the team if you have any questions, issues, or feedback.


