Tuesday, 16 July, 2019
Development Diary #1
 Jon Pither
Jon Pither We launched XTDB (known as "Crux", at the time) at the inaugural Clojure/north in Toronto in April of this year, 2019.
So far, so good. People have started using XTDB, to the extent of swapping out some of pluggable modules for their own, to better fit their organisational requirements. An example is a team wiring in their own Active Objects event log.
Our immediate plans are to make XTDB a more approachable product to use. The foundation is there - an unbundled architecture with a bottom-up design to serve bitemporal queries with ease of data eviction - but there is a risk that it could be seen as esoteric/academic, whereas we built XTDB to be used in the general purpose sense of the word "database".
Therefore over the next couple of months we will publish tutorials and videos showing how easy XTDB is to use. At its heart, XTDB is a document store that you can smash EDN maps into. There’s no need for configuring upfront schemas, and XTDB indexes everything at the top-level of the supplied document to make it available for query (here exists a useful rule of thumb: put fields you don’t want indexed into a document sub-map).
Our technical lead - Håkan Råberg - built the query engine and tested it using test suites such as LUBM (Lehigh University Benchmark from Lehigh University) to validate our SPARQL-equivalent query capability, and WatDiv (Waterloo SPARQL Diversity Test from the University of Waterloo) to stress-test the engine.
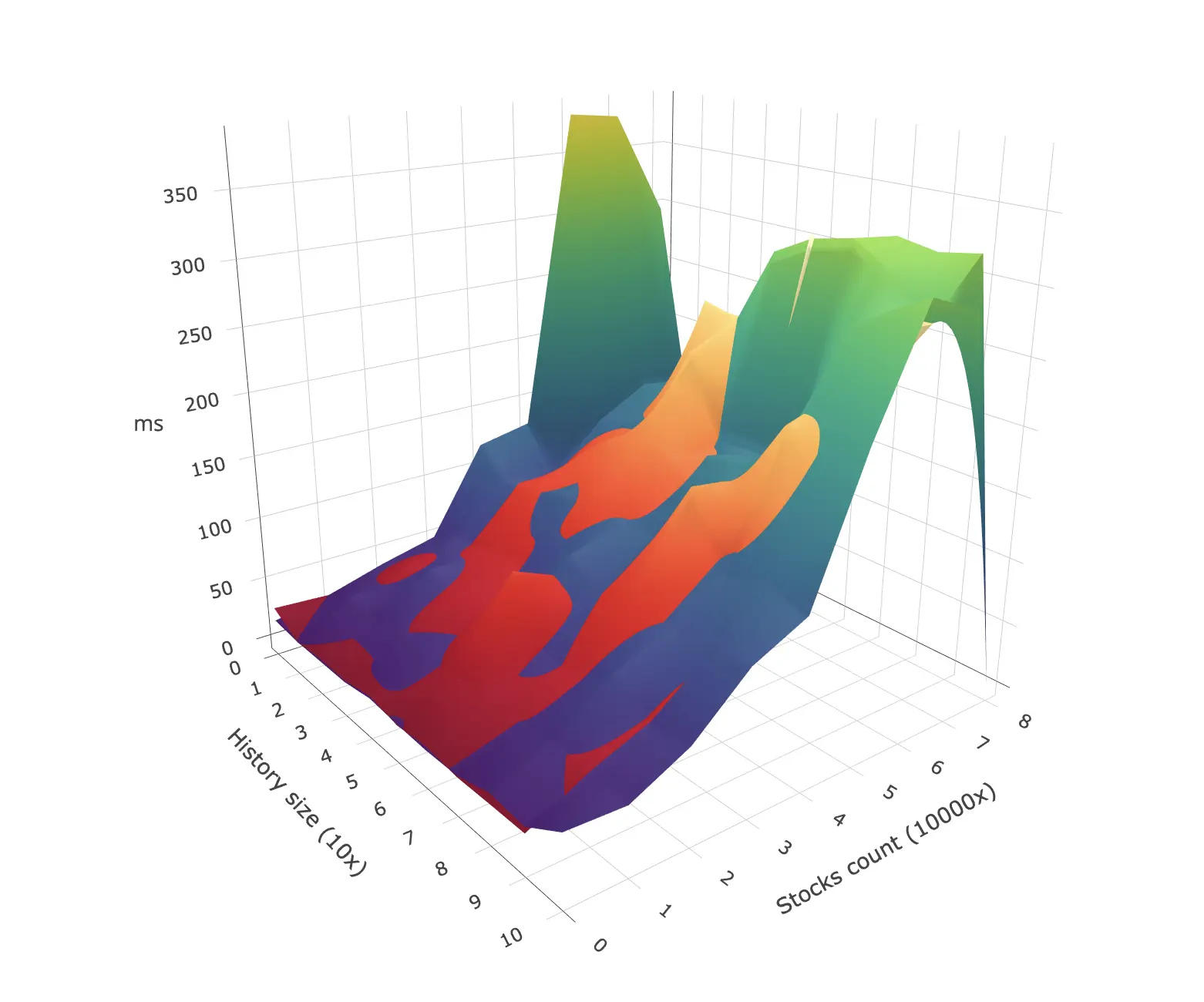
The engine uses a Worse Case Optimal Join algorithm, and it benchmarks well against competitive products. We have plans to iteratively speed it up further through cache-usage optimisation, and it’s on our short-term roadmap to publish our benchmarking results.
XTDB has been in development for around 18 months at the time of writing, and it was born in the embers of projects that we felt necessitated its development. We have always felt strongly that bitemporality is an essential capability for a temporal database, but existing options in the marketplace weren’t enough. We wanted to use a product that had the ease and power of supporting Datalog, and also one that married well into enterprises where there existed event streaming architectures built using tools such as Apache Kafka. We also wanted a product that was pluggable (i.e. internally unbundled), customisable, and crucially, open-source.
And so we built XTDB. I wrote the very first version that offered some basic query functionality using a Triple store, before Håkan came in and refactored nearly all my code away (he called it 'leanification'), to use his document-store approach. The document model offered simplicity and better promise of playing nicely with the other features we needed: bitemporal query, range searches, and data eviction.
By the end of a second phase, with Håkan at the helm, we had an MVP of sorts. We took a 2018 summer’s break, and we ramped up development through subsequent phases with the addition of engineers Patrik Kårlin and Ivan Fedorov. We also managed to attract an 'Offering Manager' from IBM - Jeremy Taylor - who is now, to all intents and purposes, running XTDB.
Ahead of us we’ve got a roadmap that we passionately want to see delivered, and so there’s a feeling of pressing down on the accelerator, to make XTDB more compelling and attractive to use.
We’ve split up the XTDB repo, from
monolith into sub-modules, and now you can see with a glance what
unbundled parts XTDB comprises of. There’s xtdb-core, xtdb-kafka,
xtdb-rocksdb… and there’s an xtdb-jdbc that’s in the works, fast
approaching a formal release status.
One piece of feedback that has come our way, is our endorsement of Kafka as the event-log and golden primary store of choice. Kafka is great, but when massive scale isn’t your objective and you don’t want the operational burden, then the only other option we currently support is to use XTDB in a 'standalone' node configuration, using a local-disk based event-log.
The new JDBC event-log is more of a 'goldilocks' middle-ground option. We can use an existing JDBC compatible database as the event-log, meaning that in the cloud, where database-as-a-service offerings are common (i.e. AWS RDS), then XTDB doesn’t require much setup at all. You can use XTDB as an embedded library in your application instances, where the nodes will fetch the data they need for local indexing purposes straight from the JDBC store (Postgresql, Oracle and more).
A JDBC setup may not necessarily scale as well as Kakfa for ingestion and replayability, but if you’re not interested in immense scale, and if you’re comfortable working with cloud-based relational databases, then this approach could be for you.
I do feel obliged to say that if you are concerned about managing a Kafka setup, then check out this very recent and extremely competitively priced managed Kafka hosting service provided by Confluent, with no minimum pricing or need to think about brokers.
We have further plans for XTDB. We intend to grow our development team first
and foremost with imminent additions, and then we intend to release the XTDB
Console that Ivan and Jeremy have been cooking up. We will publish
reproducable benchmarking results - triggered daily from CircleCI - and then we
intend to build transaction functions, for the case where Compare-and-Swap
simply doesn’t cut it (I’ve learnt that what you thought you needed transaction
functions for, you can often just do with CAS, which has much less overhead to
manage).
Beyond the main product updates, we have been busy working with community members, clients and partners, and generally ramping up for conferences, webinars and meetups. Replays from the recent XTDB Night (well, ok… it was called Crux Night at the time) in London (hosted by Funding Circle) will be available soon. Jeremy and I will be speaking at Strange Loop in September. And finally, many of the JUXT team will be attending Heart of Clojure in August. We hope to see some of you soon!
Thanks for reading this journal. Please give XTDB a try and see if it fits for your document store and Datalog query needs. Our official support channel is the 'Discuss XTDB' forum, and we also monitor the #xtdb channel on the Clojurians slack. You can also reach us via hello@xtdb.com.