Sunday, 28 March, 2021
The Strength of the Record
 Steven Deobald
Steven Deobald 
The computer is a curious gadget. It is one of few human inventions which can exist purely — yet accurately — in the imagination. Prior to the existence of a real computing machine, mathematicians could hypothesize how it might behave. They even understood the unbounded, fractal potential of computers: If human beings have machines for computation we also have the atom of computation and we can recombine these atoms to great effect. Our largest and most complex computers were borne of tiny, simple computing components.
Cixin Liu visualized this agglomeration beautifully in The Three-Body Problem. Liu imagines the characters of his book playing an open-world, emergent MMORPG. The players, who know nothing about computer design, create a functional computer in-game (a la Minecraft) through the composition of thirty million other players, with each of those thirty million individuals acting as a computational gate. An expanse of desert acts as Liu’s silicon wafer under the gates of his meat computer. Quite naturally, the username of the player who creates the computer is Von Neumann.
Whatever hardware brings a computer to life — whether soldiers in the desert or transistors on silicon — its various parts require names. Liu’s fantasy human computer has registers, stack memory, a system bus, and a hard drive. Most of his components consist of people raising and lowering flags to control the flow of data, with one exception. Scholars with notepads comprise the hard disk — a notion we’ll revisit in a moment.
Liu’s component names all seem obvious to us, due to their twenty-first century ubiquity. But why these names? If I had never heard of a computer before, would I consider stack memory emblematic of a stack of cards or would the name seem arbitrary? When we pick apart a label like "system bus", and thus the etymology of "omnibus", we begin to see the exercise of naming things in two parts. The first, and more obvious, is the coining of terms. The more important second part is the construction of metaphors.
Broken Metaphors
We only need to revisit some Today Show clips from 1994 to recall how alien computers and computer networks were just three decades ago. In 1991 a computer was a magical box of infinite possibility. A computer — a real computing machine — is by its very nature an abstract thing and thus has always been so much more than a better calculator or a fancier accounting ledger. And yet, paradoxically, that’s precisely how we use computers today. Computers coordinate the most mundane aspects of the global economy, send me a message when my library book is due, or record a family’s new home in the government’s Land Titles database. The sprawling mycelium of computing devices across the globe behave, in aggregate, much more like the robots of retrofuturism than any of us are likely to acknowledge. The robots take us shopping and help us with video calls to our aging parents. The robots are ubiquitous, invisible, and heart-breakingly banal.

Our prosaic robots exist at every layer. The robot is the L2 cache, Linux, and Google Maps. Is it little wonder that we, the techno-elite, construct some brittle metaphors as we climb from XOR gates and system buses to the abstractions that reach the fingertips of the humans? Along the way, we hold on to some outdated metaphors from earlier days of computing. EOT (End-of-Tape) markers show up less commonly in software these days but a modern programmer won’t blink an eye at an EOF (End-of-File) marker of the same lineage. As computers entered the mainstream, "directories" of files were given the thin coat of paint known as "folders", producing the increasingly-peculiar physical metaphor of putting your files inside of folders inside of folders inside of folders. The "filing cabinet" metaphor had a more timely death. My last memory of the filing cabinet is Windows for Workgroups.
Of course, we need not restrict ourselves to the tangible world of buttons, files, and folders. We programmers kick ourselves with broken metaphors all the time while programming the robot’s innards. Remember when we used "object-relational mapping" libraries to write objects to disk? Those were heady days, weren’t they? [1] I still remember my first glimpse of the Rails ActiveRecord implementation. has_many :simply_darling_little_macros was an epiphany back in 2004 for those of us stuck wiring the fields in our POJOs to database columns by hand like mid-century telephone operators hard-wiring networks of voices, one at a time. Yessir. ORM was a thing of beauty, compared to her contemporaries. Every day at 8:00 AM I would grab a steaming cup of loam-flavoured American drip coffee and sit back to enjoy the DHH Show — marveling at his juxtapositions: a quagmire of Spring XML against his elegant Ruby macros. But that’s not what I’m talking about.
The real question is: Why were we mapping anything at all? Why was anything required to save an object / record / document to disk beyond this?
Compare this ActiveRecord [2]…
class Facility < ApplicationRecord
belongs_to :facility_group
has_many :phone_number_authentications
has_many :users,
through: :phone_number_authentications
has_and_belongs_to_many
:teleconsultation_medical_officers,
-> { distinct },
class_name: "User",
association_foreign_key: :user_id,
join_table: "officers"
has_many :encounters
has_many :blood_pressures,
through: :encounters,
source: :blood_pressures
has_many :blood_sugars,
through: :encounters,
source: :blood_sugars
has_many :patients,
-> { distinct },
through: :encounters
has_many :prescription_drugs
has_many :appointments
has_many :teleconsultations
has_many :drug_stocks
has_many :registered_patients
has_many :registered_diabetes_patients
has_many :registered_hypertension_patients
has_many :assigned_patients
has_many :assigned_hypertension_patients
...
end
facility.save…to an XTDB entity…
[::xt/put facility]Today, ActiveRecord is void. Mapping objects into databases is outmoded. The idea has a certain appeal, no doubt. I record (verb) my records (noun) to disk. When they are read back into memory via has_one :superfluous_abstraction the virtual machine makes them active — singing, dancing, and procreating through the object lifecycle — until they are recorded back into Postgres. But this act of recording doesn’t necessitate mapping. Object mapping is a broken metaphor.
In fact, object mapping is a broken metaphor built on broken metaphors. We have a User object in memory we want to save to disk. That’s all. Instead of a command equivalent to "computer, save the user" we are met with forty years' worth of anachronisms. We must worry about join tables, floating point value coercion, and whether or not our TIMESTAMP columns are automatic.
The mapping is a symptom; the anachronism is the disease. Our objects can and should maintain symmetry with the database unless we tell them otherwise. To do so, we must choose a new storage metaphor for the next forty years.
The Contestants
End users understand the metaphors of buttons, folders, and desktops as user interfaces. So it is for us developers and our database metaphors. There is some surface area to a database that allows us to store, query, and listen. This is our user interface. It is also our storage metaphor.
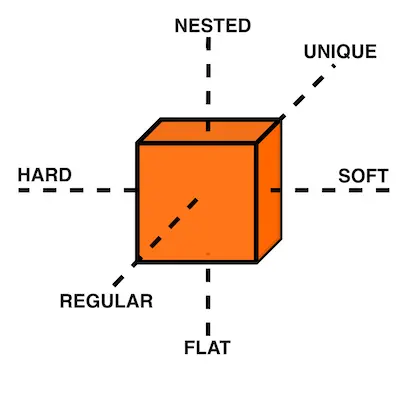
Storage metaphors come in three broad structural categories: rows in tables, documents in trees, triples in graphs. These structures, in turn, are bound to a three-dimensional field. Our X-axis is schema, from hard to soft, our Y-axis is depth, from flat to nested, and our Z-axis is shape repetition, from regular to unique. Positioned within this cube, any given structure represents the form of our database.
Each structure has a preferred location within the cube. Rows in a relational database table will subscribe to a hard schema, a flat depth, and a common shape. Document stores will subscribe to a softer schema, a nested depth, and (potentially) unique shapes. Triples do not dictate schema by their nature but they have negligible depth and negligible variety. The uncomplicated nature of triples is reminiscent of LISP’s absence of syntax. That makes them attractive… but esoteric.

|
Note
|
There are visual examples provided for each storage metaphor’s preferred structure. They are intended to be fun and illustrative rather than realistic and boring. |
Tables: the hometown favourite
I was fifteen years old in 1996. My highschool had an "Information Processing" class for Grade 10 students, from which I distinctly remember an argument between a close friend and the teacher while they stooped over a PowerMac running ClarisWorks. My friend insisted that learning a spreadsheet was unnecessary since the word processor already provided "tables". Although my teacher understood that the word processor’s tables were insufficient for accounting, I do remember his argument eventually came down to "just trust me on this one" rather than diving into the semantics of ClarisWorks' internal data representation. My friend’s confusion was only exacerbated the following week when a desktop database was added to the mix. In his mind, a table is a table is a table.
It’s easy to see where this confusion comes from. Most people do not care what a computer thinks about rows in a table. A table is an intuitive concept, even to children. But we all know, just as my teacher understood, that text in an arbitrary table is effectively meaningless, text in a spreadsheet table is meaningful but unconstrained, and text in a database is constrained by datatype. When your tables have constraints you can build schema, views, atomic writes, and table-to-table relationships on top of them. That’s powerful stuff.
Looking back at Cixin Liu’s "hard drive" comprised of scholars with notepads, our confidence in the meat computer is likely to go up if we can put some hard limitations on what kinds of data the scholars are allowed to write, and where. The scholar who writes whatever she wants wherever she wants is not a very useful component. She must adhere to the sensibilities of the computer.
Tables are powerful precisely because of their handicaps. They are not mathematically perfect constructions sent to us from the Heavens or Harvard. [3] Instead, they are intuitive, flat, and readily map to business processes. Tables have served us well for three or four decades and most businesses can still survive on software built with tables alone. For a while. Businesses in the 1990s could survive on paper for a while, too.
Documents: structs, trees, and nests
Skip ahead nearly a decade to 2004. I stumbled across Prevayler during my years at University. "10,000 times faster than Oracle? This thing is going to be huge," I thought. We all know how that turned out. Years later when my younger colleagues were getting excited about Couch and MongoDB, I found myself put off by the lack of standard querying and the entire shoot-from-the-hip attitude document databases were pitching. "Schemaless! No SQL! Just shove things in the database and figure it out later!" No thanks.
Over a decade later, I don’t know of a single object database or document database in those ex-colleagues' production systems. Everyone uses Postgres. Why?
Object DBs simply never took off. An object isn’t a simple or intuitive concept; an object is type-matching dynamic dispatch implemented over a collection of closures which in turn share a second collection of lexically-bound variables which themselves are — you guessed it — more objects. [4] These trees of objects are nested indefinitely. Many of us have made a career out of object-oriented programming but the essence of an object is message passing, not structs for disk serialization.
Document DBs, on the other hand, were not such a bad idea. They were just poorly implemented. Standard query languages? Nope. Schemaless? Nope. Relationships? Not really. Append-only, immutable data? That gets pretty expensive when you denormalize all your records into a deeply-nested rat’s nest.

Developers want languages built on research and standards. Even a fragmented standard like SQL is better than a homebrew query language. MongoDB lacked basic joins until version 3.2 but this was an honest mistake. MongoDB engineers believed their customers could survive on schemaless, denormalized data with no relationships. We now know this isn’t true. All databases have schema. [5] All databases have relationships. [6] Our schema and relationships may be implicit but they are truths we must face.
Neo4j, on the other hand, is a document database that actually works. Neo4j is a property graph and property graphs do not pretend relational data doesn’t exist — or that it exists but somehow isn’t important. Unfortunately, Neo4j has its own homebrew query language, Cypher, with its own baggage. Although an open standard since 2017, Cypher queries are difficult to compose because the language lacks a foundation in logic:
From the perspective of a formal query language, it is a mess — with structures that break compositionality for no good reason, and it remains a good 70 years behind the frontier of formal graph logic.
Graph Fundamentals — Part 2: Labelled Property Graphs
Rather than hide behind a deeply-nested document model or inglorious query languages, we can put our faith in decades of research. Computer Science tends to invent things long before they hit the market so it’s likely a high-caliber document store need not invent anything from scratch. An immutable document store supported by a well-understood query language for traversing relationships would feel natural to users and developers alike — the best parts of MongoDB and Neo4j without the dross.
Triples: oh, the trouble with triples
Skip ahead another decade to 2014. Clojure already won my heart prior to its 1.0 release in 2009. By 2014 I was building a company on it. I was excited about the possibility of Clojure-style simplicity in database form: The triple-store.
Roughly, there are two categories of triples: RDF triples, which attempt to encode relationship semantics, and EAV triples, which only encode the relationship. A semantic triple might look something like [Bob belongs_to CommunistParty] where an EAV triple is more likely to take the shape [Bob :party CommunistParty]. Rather than debate the semantics of semantic triples, we’ll treat them as loosely equivalent for this story. Caveat lector.
My team was immediately attracted to triples. The declarative logic of Datalog, with its Prolog origins, felt like the perfect way to ask questions of a database. Having never worked with triple-stores before, there was a purity to EAV triples none of us had ever imagined possible during our career with relational databases. An immutable store of pure facts? Count us in!
Alas. Just as a child grows up and learns her parents and teachers are not infallible, so does the star-struck developer seduced by the siren song of purity. I know better now. These days, when I read my friend Abhinav’s Haskell articles, full of beautiful and orderly code, I look back on my time with the triples and remind myself that purity can be a dangerous waste of time. Rather than squandering my finite time on this planet searching for the bottom of the purity rabbit hole, I instead watch Haskell from afar with profound respect and terror.
[63 :db/ident :user/name]
[63 :db/valueType :db.type/string]
[63 :db/cardinality :db.cardinality/one]
[64 :db/ident :user/url]
[64 :db/valueType :db.type/string]
[64 :db/cardinality :db.cardinality/one]
[64 :db/ident :user/stream]
[64 :db/valueType :db.type/ref]
[64 :db/cardinality :db.cardinality/many]
[64 :db/ident :post/user]
[64 :db/valueType :db.type/ref]
[64 :db/cardinality :db.cardinality/one]
[64 :db/ident :post/title]
[64 :db/valueType :db.type/string]
[64 :db/cardinality :db.cardinality/one]
[64 :db/ident :post/body]
[64 :db/valueType :db.type/string]
[64 :db/cardinality :db.cardinality/one]
[64 :db/ident :post/likes]
[64 :db/valueType :db.type/ref]
[64 :db/cardinality :db.cardinality/many]
[1234 :user/name "Joe"]
[1234 :user/url "..."]
[1234 :user/stream [9090]]
[5678 :user/name "Jane"]
[5678 :user/url "..."]
[5678 :user/stream [...]]
[8912 :user/name "Lu"]
[8912 :user/url "..."]
[8912 :user/stream [...]]
[9090 :post/user 5678]
[9090 :post/title "today"]
[9090 :post/body "go fly a kite"]
[9090 :post/likes [8912 1234]]Back in 2014 our triple-store of choice had a hard schema, not unlike the schema definitions in most relational databases. However, it went so much deeper than that. Creating schema for our facts felt like Carl Sagan’s famous quote, reified: "If you wish to make an apple pie from scratch, you must first invent the universe." We really wanted to build our system out of triples but it felt as though we were bootstrapping the universe just to get to square one. Square one, as it turns out, is simply:
[::xt/put record]We found that bootstrapping wasn’t our only challenge. Schema or no schema, triples are not really natural. Beautiful, yes. Pure, yes. Natural, no. Try as we might, the team never had the epiphany with triples we had each experienced with Clojure.
In retrospect, it feels as though there must be an underlying reason RDF has never enjoyed general database success. Despite more than two decades of research and implementation, RDF remains the storage metaphor of museum artefacts and government statistics. [7] [8] The elevation of purity above all else is a certainly one problem with triples. Their true deficiency, however, is hidden in plain sight: triples by their very nature only describe relationships. Despite their name, relational databases consign the very notion of a "relationship" to the realm of the derivative. Triples have the opposite problem. Triples treat nouns as second-class citizens.
Enter The Record
What exactly is a "record"? To understand the record completely, we must look back over the history of computers, back over businesses which predate computers, and back over all of recorded human history. Before we take that trip, though, let’s quickly read the first dictionary entry:
a thing constituting a piece of evidence about the past, especially an account kept in writing or some other permanent form
Computer Scientists will understand: "evidence about the past" is equivalent to "facts on a timeline" and "permanent form" is a synonym for "immutable data".
Once upon a time in computing history, tapes were composed of files which were composed of records. It could be argued that the "record" is actually the most natural of the three, given that humans have been organizing information into records since long before the computer. Sometimes those records were flat rows in an accountant’s ledger but they were often written on card stock:

These sorts of records can be seen for hundreds of years into humanity’s past, at least as far back as the double-entry bookkeeping of 14th Century Venice. It could even be argued that all three storage metaphors we’ve examined so far — the table, the document, and the triple — can claim the title of "record".
But relational databases fail the dictionary definition. Most lack a meaningful, first-class representation of time with which to view the past. The flip side of that coin is the absence of immutability. If you want immutable records for your inventory table you are often stuck managing an inventory_audits table in the application tier… wastefully duplicating the built-in Write-Ahead Log of your database in the process.
Triples fail our mental model instead. The client record card is natural. Specifying each individual fact about your client is not. If we want to see that natural record, triples force synecdoche on us. We must ascribe meaning to identities so triples like [Bob has_email "bob@newhart.com"] and [Bob has_phone +15551234567] can be glued together into "Bob". The truth is, there is no "Bob" — only facts about Bob. If triples are to say anything about the form of the data they contain, we must slather them in complicated ontologies.
It is possible to find a middle path between hard, flat rows in tables and infinitely malleable triples. Surprisingly, documents are that middle path.
Records: doing documents right
"Flat is better than nested" is a guideline, not a rule. If we can employ nesting conservatively, the storage metaphor of "documents" can avoid the MongoDB rat’s nest. If we add a standard query language to that, we may really be on to something.
The Client Record Card from a few paragraphs ago is a useful visual aid — it is both a record and a document. "Address" is embedded within the card but the physical constraints of the card prevent us from nesting nests of nests the same way we enjoy foldering folders of folders. Nothing crazy is happening.
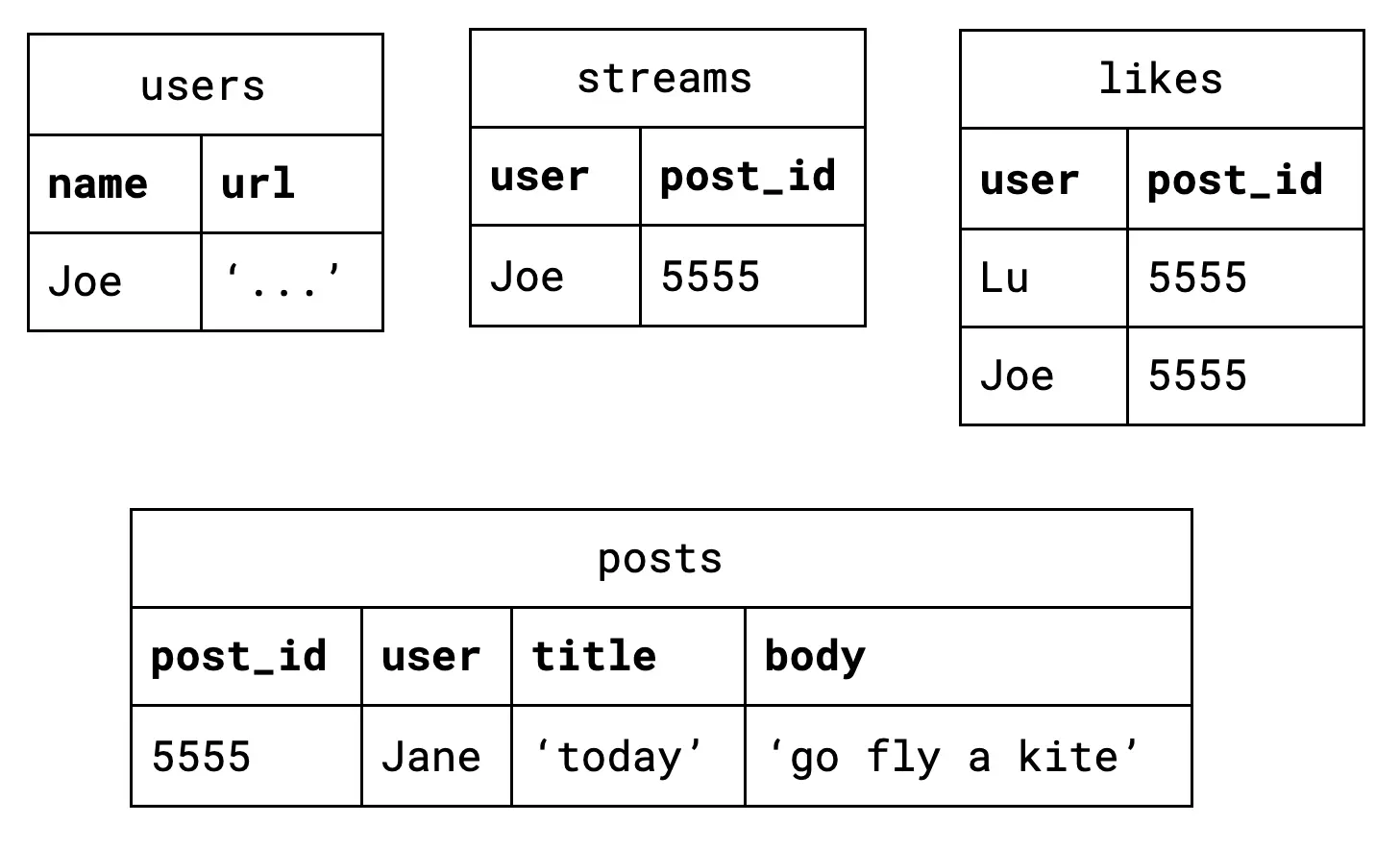
Any developer who has sent or received data over an HTTP API in the past ten years is already accustomed to this sort of document. We can all imagine encoding this card in JSON. Nothing crazy will happen.
To ensure nothing crazy will ever happen, our storage metaphor of "documents" must play by the rules. The dictionary says our database must store immutable facts on a timeline. [9] Computer Science says our database must speak a standard query language. Our experience and intuition says our database should provide us lightweight references between our documents and discourage deep nesting.
{:user/name "Joe"
:user/url "..."
:user/stream [9090]}
{:user/name "Jane"
:user/url "..."
:user/stream [...]}
{:user/name "Lu"
:user/url "..."
:user/stream [...]}
{:xt/id 9090
:post/user "Jane"
:post/title "today"
:post/body "go fly a kite"
:post/likes ["Lu" "Joe"]}These are not abstruse or mystical ideas, but they do demand a reappraisal of the database. We can’t just tack immutability onto MongoDB or temporality onto Postgres. [10] We must rebuild the foundation. We must record a graph of immutable facts on a timeline tolerant of growth and query them by time-aware logic. That’s a mouthful, so let’s just call it a Record. This is the new metaphor.
Liu’s scholars in the desert would do precisely this. Each scholar’s document may refer to another scholar’s document. The system (and the user) must be able to read the documents — consistently. Given enough paper, the scholars would never scribble out old documents and rewrite them. Instead, they would maintain a record of every document they’d ever written, ordered by date. The documents are the audit log. Whether we say record or document, the storage metaphor is the user interface for the scholars, just as it is for us.
A copy of this article can always be found at this permanent URL: https://v1-docs.xtdb.com/concepts/strength-of-the-record/
This work by Steven Deobald for JUXT Ltd. is licensed under
CC BY-SA 4.0. ![]()
![]()
![]()


