Thursday, 17 March, 2022
Peace, Love and Data Mesh
 Steven Deobald
Steven Deobald Hacking, whether on tax software or Quake III, is a joyful process. Yet our industry has a habit of draining the joy out of building software when it comes to data architecture. If you read Oracle Magazine back in 2002 you’ll remember the feeling of the articles: dusty, flavourless, grey.
When I first came across the term Data Mesh I feared it would bore me to sleep in the same way other data architectures (perhaps named for water bodies) have in the past. But the more I read about data mesh, the more it seems to represent a small organizational and technological revolution.
Data Mesh 101
The original article on data mesh feels a bit scattered on the first read. There’s a lot happening in there, and it’s not entirely clear which pieces exist at what zoom levels, which pieces might be optional, and when, exactly, an organization might receive their first data mesh Gold Star.
But the second article builds on a scaffolding of principles, making it much easier for the reader to grok data mesh as a concept. In brief, those principles are:
-
Data Ownership by Domain (At-Source)
-
Data is a Product (First-Class)
-
Data is Self-Serve (Ubiquitous)
-
Federated Data Governance ("Governed Where It Is")
Note the parentheses. Like Agile and Microservices before it, data mesh isn’t one thing. Synonyms and interpretations already exist. The Confluent interpretation of data mesh is naturally very Kafka-heavy. Microsoft, when it starts talking about data mesh, will probably speak in terms of Event Hubs and SQL Server. This is a good thing. As the global community slowly arrives at a loose definition for data mesh, we will increasingly see concrete examples and variations which sharpen our collective understanding.
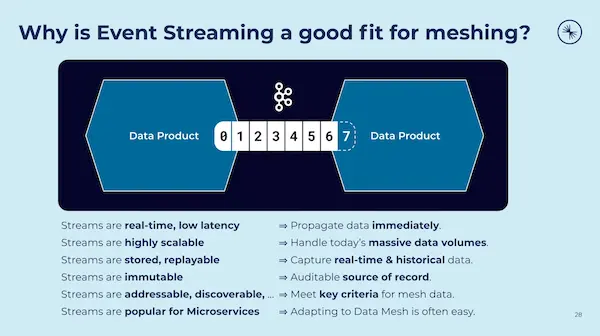
We are less likely to see the organizational ideas of data mesh co-opted by companies like Microsoft and XTDB, however. When you listen closely, the language of data mesh says some peculiar things. The data mesh folks speak in terms of deep organizational and technological change. Data Mesh says these are part and parcel of the new architecture. Data Mesh experience reports sound like case studies from Reinventing Organizations, not an Oracle Magazine article about maximizing ROI by exploiting query plan internals. In conference talks on data mesh you’ll hear phrases like "foster empathy" thrown around in discussions about collaborative, decentralized, servant products built out of emotional incentives.
That’s hippie talk right there. And that’s precisely the bit that has us excited about data mesh.
What does a Data Mesh look like?
For many, it’s easier to understand data mesh in terms of what it isn’t. A data mesh is the philosophical adversary of the classic data warehouse. It is the data lake’s next of kin.
A data warehouse is a compelling visual, even if you’ve never used one. Millions of boxes, manually selected, tucked away neatly on deep shelves, organized top-down by a pot-bellied, cigar-smoking warehouse manager. The warehouse ETL jobs are forklifts and conveyor belts, performing pre-defined transformations. The data is groomed from the beginning. It’s ready for analysis the moment you pluck a box from the shelf.
A data lake, on the other hand, is the free-wheeling alternative: no selection, no neat tucking away, no top-down management, no transformations. The data lake is intentionally raw, unrefined, and disorganized. Analysis time? You need to groom that data yourself. All the data lake achieved was heaping all the data together in one giant pile.
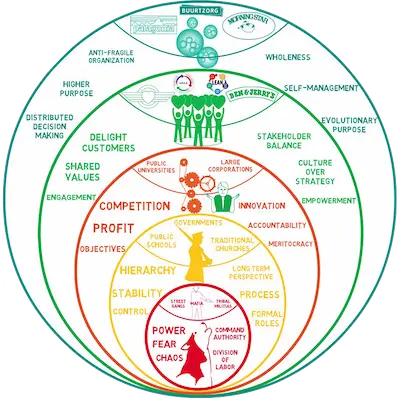
Reinventing Organizations describes a colour-based maturity model, in which organizations grow through red, amber, orange, green, and teal categories. [1] Red organizations are tribal, like the mafia. Amber are hierarchical, like most governments. Orange are objective-driven, like most large corporations. Green emphasize delighting customers and employee empowerment. Teal value distributed decision-making and wholeness. Without dragging the analog too far, it’s easy to imagine a data warehouse as amber or orange and data lakes as green. Data Mesh is a teal-toned architecture. If your teams aren’t sufficiently mature to collaborate on a unified but distributed vision — whether or not that vision has anything to do with computers — they’re likely to struggle with data mesh.
For this reason, the advice from early adopters of data mesh is consistent: start small. Begin with mature teams who are capable of owning their data at the source while making it discoverable to the entire organization. Allow those teams to exemplify what "data as a product" means to your company so others can follow.
Part of the reason this intentional, evolutionary approach is so necessary is because "data as a product" is such an abstract concept. There is no literal product to buy, no service to sign up for.
In fact, the specifics of your data mesh are surprisingly unimportant. You might glue your organization’s data together with Kafka. But you might instead opt for violently efficient messaging with, say, Aeron. [2] One of your teams might pile raw object files into S3, datalake-style, and another might expose a careful schema over GraphQL. It doesn’t matter what materials you use for the nodes or fabric of the mesh. As long as your mesh adheres to the principles, you get your gold star.
Here is an example data mesh archicture shared by Tareq Abedrabbo of CMC Markets at QCon Plus in early 2022. It includes both Kafka and Aeron for messaging, as well as Amundsen for data discovery and DynamoDB for storage:
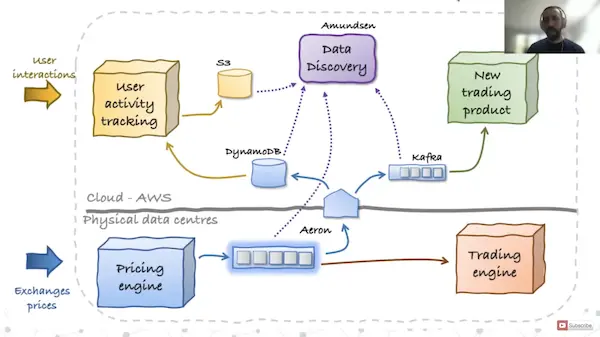
Despite building a complex and performance-sensitive financial system, Abedrabbo still speaks in Teal terms: data must be human-friendly, evolutionary, and prefer usability over completeness. "It’s about the journey — seek alignment. It’s a shift in mindset toward decentralized and collaborative data."
While it’s a pleasant surprise to watch Wall Street engineers let their freak flag fly, there are obviously some technical details to consider. Even though the specifics don’t matter, the capabilities of your tools matter a great deal. It wouldn’t have been possible to build a data mesh twenty years ago.
Here come the buzzwords
Watch a presentation or two about data mesh implementations and you’ll hear a chorus. [3]
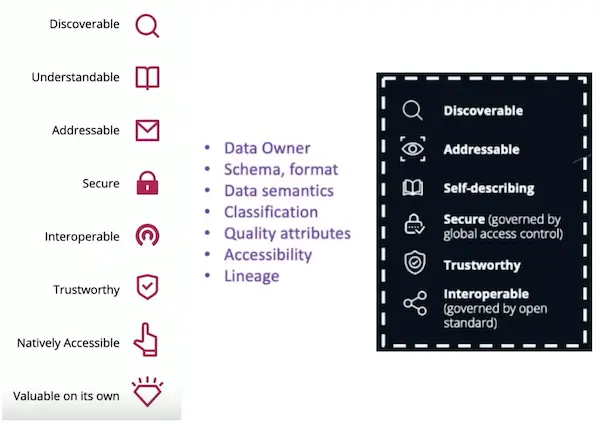
Some of these qualities get more emphasis than others. Like the four data mesh principles, they’re also described in multiple ways. For instance, "trustworthy and truthful" and "lineage" are often used as synonyms for "immutable", and vice-versa. As a consequence, there exists an events/states duality that some advocates still struggle with. We have immutable events in spades — in 2022, any event sourcing system worth looking at is immutable by default. Unfortunately, the same can’t be said for databases yet.
"Data agnostic tools" are another example. Like much of data mesh, this is easier said than done. An analytics or time-series database that expects your teams to shoehorn data into a particular shape are not "data agnostic." Abedrabbo puts agnosticism in the spotlight when he says:
Data itself is neither operational nor analytical — use cases are.
The buzzword we’re prying for is HTAP: Hybrid Transactional Analytical Processing. (HTAP can be thought of as the state-serving side of the coin in a Kappa architecture.) The data mesh gospel leaves no space for an OLTP/OLAP duality in data stores which embrace the ideal. If users of data go to the owner of the domain to find the data they need, that owner should have the capability to serve both operational and analytical use cases.
Let’s look at the qualities of a data mesh under the lens of each principle.
1. Data Ownership by Domain
Originating in Domain-Driven Design, the concept of a shared vocabulary has grown up into a shared narrative. A business is a story its employees tell together. Domain-Driven Decentralization is the idea that the source of the data — the owners of a particular domain (be it billing, legal, whatever) — should create discoverable, self-describing data products.
Combined with "self-serve data" (principle 3), this is really the idea that brands the data warehouse as an antipattern. Domain-oriented (micro-)services are often described as the computational parallel to domain-oriented data products. No one wants to deal with a late-90s monolith service anymore. Why would we want to deal with monolithic data stores?
There are some natural consequences to domain-owned data. The data is trustworthy because it is served from the source. Discovery (and possibly federated schema) is necessarily impressed upon the data, since there’s no longer a single "source of truth" for users to look to.
It is hard to imagine distributed data teams creating trustworthy data without immutability as the foundation.
2. Data is a Product
Collaboration begins here. If the data is a product, it has to be addressable somehow — a Kafka topic, a URL, Parquet files, a SPARQL endpoint, something. If each domain’s data is subject to evaluations of quality (Dehghani suggests a Net Promoter Score, but snide comments at the lunch table work too), the team producing that data will want their work to be seen as high quality.
If the team is mature, they will think of the data they serve as a product in the same terms the utility company thinks of electricity and Tesla thinks of cars. A utility company is a servant to its customers. Tesla wants to delight its drivers. The products provided by those companies are first-class — there is nothing more important to their business than the product they sell. So it should be with data products.
Again, quality and honesty is in no small part a factor of immutability. More mature organizations will also recognize a second layer to immutable data: temporality. If the same data is to serve both operational and analytical loads, it needs to be bitemporal. If the data is to have self-describing semantics, it needs to have schema-on-demand. Entities in such a system (like XTDB) are inherently polysemic (multi-domain). This is important since the modeling of polysemes is a core component of data mesh.
3. Data is Self-Serve
Self-serve (ubiquitous) data has to break free of the artificial operational/analytical duality, but it also needs to adhere to open standards. Query languages can’t be ad-hoc — they need to be based on standards like SQL and Datalog. Data on disk can’t be locked into closed formats or closed-source tools.
Again, immutable data (lineage) is an absolute requirement — if the data is self-serve but changes every day, it’s not helping anyone. Data customers must be able to reconcile the data they’re consuming. Kafka and other event-sourcing infrastructure is the natural modern fit for event-oriented data. Self-serve, immutable, state-serving data nodes demand an immutable database.
4. Federated Data Governance
Even organization-specific standards such as schemas and schema registries need to play by the same rules. One such tool is the Egeria Project (creators of the Egeria XTDB Connector) — a Linux Foundation and IBM project for creating tool-agnostic open metadata and governance.
Federated Data Governance must happen this way. Gone are the days when data governance was the province of a central DBA team executing GRANT statements.
That said, there is still scope for authorization and governance at all layers. One such tool is Site, an open source resource server which acts as a no-code API gateway to XTDB, providing automated OpenAPI and GraphQL endpoints. Site provides governance with an authorization system inspired by Google Zanzibar.
The future of XTDB in Data Mesh
As of this writing, XTDB is version 1.21.0. XTDB is already a polysemic, schema-on-demand, immutable, graph query database built on open standards and standard query languages. This means XTDB is already a solid foundation for your data mesh nodes.
But there’s a lot more we want to do. The XTDB team is deep in development, building this vision.
On the front end, we are building a ground-up, SQL:2016-compatible query engine. Over the past year, we have come to the conclusion that SQL absolutely must be a first-class feature of XTDB so data scientists and business analysts will fall in love with it just as much as developers have.
With immutable records and bitemporal query, XTDB 1.21.0 is already an aspiring HTAP database. But we’re expanding on this vision to make HTAP the essence of XTDB. Data Mesh doesn’t forbid mutable OLTP data or ETL jobs but it does view them as legacy, a vestige to grow out of. Immutable HTAP data sources will be key to that transition.
Part of "HTAP at the core" is building the next generation of XTDB on top of Apache Arrow. One common example of data mesh interoperability is sharing large data sets through Parquet files. But Parquet is only a space-efficient interop format. Arrow is a columnar format similar to Parquet, but intended for computational purposes instead of space efficiency. As a very happy upside to this, XTDB’s Arrow engine will be compatible with all existing and future tools targeting the Arrow format.
The other "HTAP at the core" goal of our current research is to build bitemporality in the large. Using sophisticated temporal indexes based on decades of research the next XTDB query engine will go beyond as-of and as-at queries to allow users the ability to query across time on the bitemporal plane. In concrete terms, this means that database users can answer complex temporal questions on their operational data ("for what past interval were these 5000 contracts all active at once?"). This is vastly preferable to loading everything into a time-series database and operating on stale, incomplete, or centrally-managed data warehouses — the antithesis of data mesh.
This HTAP research has one final consequence: Separation of Storage and Compute (SoSaC). With large (potentially infinite) data sets stored as immutable, temporal records forever, we can no longer assume that every XTDB node will carry the entire database with it all the time. Object storage must be permitted to live elsewhere, on cheap disks, while database nodes come and go as necessary.
How do tools enable the groovy dream of Data Mesh?
Data Mesh places some futuristic demands on your organization. Teams need to trust and collaborate, basing that trust on the honest, high-quality data they get from one another. The data mesh dream can’t be fulfilled without a small leap of faith into the world of decentralized ownership and worker empathy. By starting small, organizational changes can come hand-in-hand with architectural changes.
But the technology? It underpins the rest. Teams cannot trust one another’s data if they continue to rely on unqueryable audit logs as "sources of truth". The truth of a team’s data must be preeminant. Tools like Kafka and XTDB are finding their way into most companies, bit by bit. Most teams will trust concrete tools first. Only once they’ve grounded themselves in ubiquitous, immutable, temporal, self-describing, operational/analytical data will they learn to lean into the data mesh vibe.


