Monday, 19 December, 2022
Development Diary #8 - Seeking Performance with RocksDB
 Jeremy Taylor
Jeremy Taylor The 6 months since our last diary entry have been packed with reading, reflecting and building. Most notably the team appeared in force at Strange Loop in September.
During this period we’ve undertaken a series of 1.22.x releases motivated by a desire for improved ingestion performance. Specifically we wanted to maximise the potential for XTDB to saturate the write capacity of the underlying RocksDB engine. To support this initiative we also began work on a transactional workload benchmarking suite and associated set of tooling.
Strange Loop
Almost the XTDB entire team was in attendance at Strange Loop 2022 alongside several of our JUXT colleagues. We took advantage of JUXT’s platinum sponsor booth at the conference to discuss our ambitions for the future with a broad audience of fellow builders and thinkers.

Our very own Håkan Råberg was invited to give a talk where he outlined some of the columnar indexing strategies that we have been experimenting with. The slides are here and the recording of "Light and Adaptive Indexing for Immutable Databases" is embedded below:
Workshop
Jeremy Taylor delivered a workshop on Bitemporal Data Management reviewing SQL:2011’s temporal functionality in the context of Richard Snodgrass' original writing on the topic in his classic book "Developing Time-oriented Database Applications in SQL" (1999).
Workshop preparations prompted the creation of an interactive Bitemporal Visualizer tool:
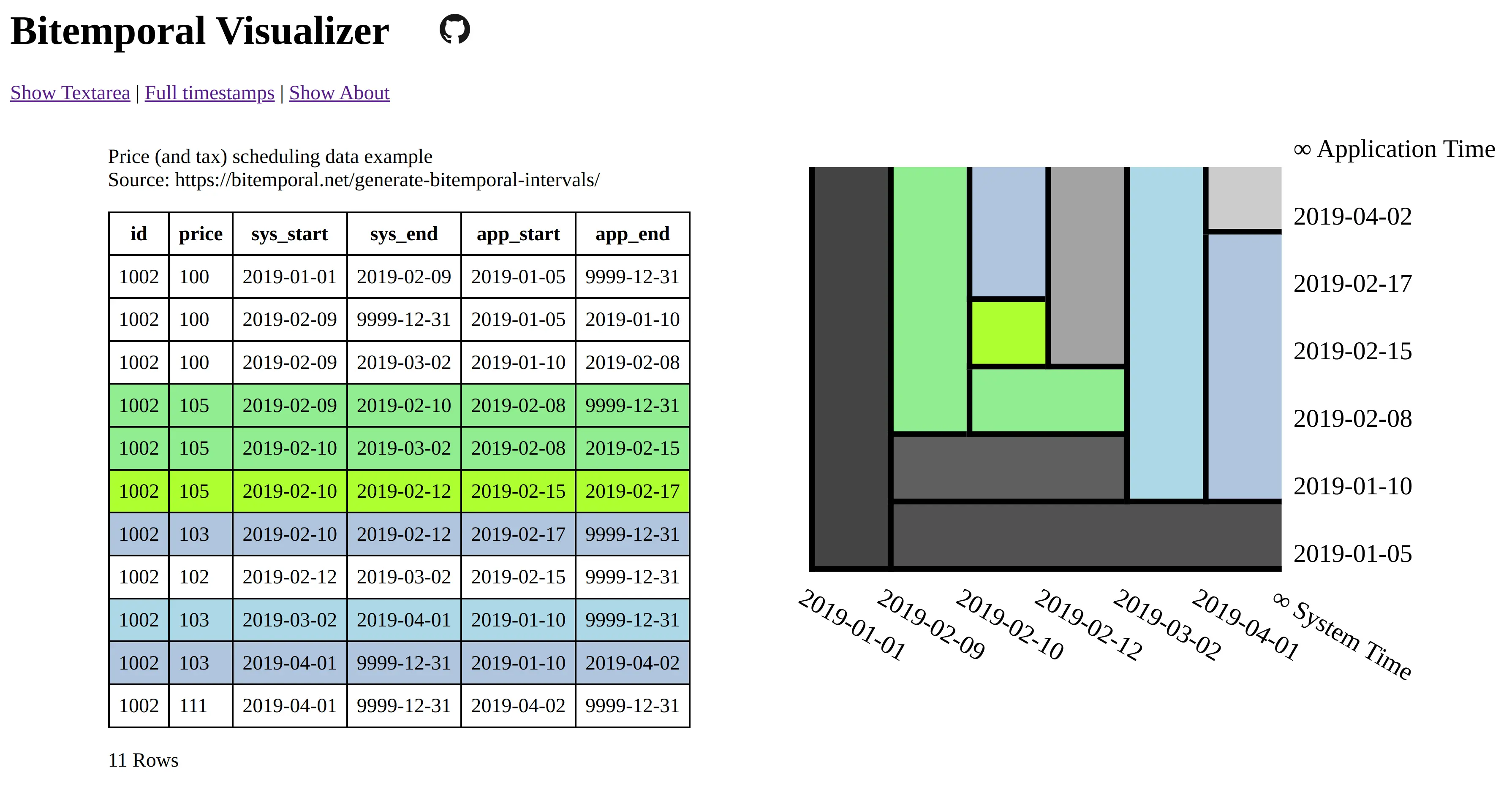
Around the conference
We were encouraged to learn that we weren’t the only people presenting on some form of bitemporal technology. A team from Morgan Stanley gave a talk on their approach to implementing declarative & concurrent semantics for their large in-house platform written in Scala, boasting features including "automated asynchronous execution; caching; a bitemporal data store; distribution; dependency tracking". Interestingly they even pointed out the parallels of their semantics with SQL. Hopefully we will find an opportunity to compare notes in the future.
In addition to being a generally fascinating conference we found the conversations with everyone who came to chat to us really valuable, whether that was in the hallway track, over a meal at a restaurant, or at our sponsor booth. From healthcare records, to inventory management, to wrangling feature metadata & skew during ML model training, to financial forecasting, to tax calculations …the variety of possible applications for XT discussed was enormous.
We are especially glad that so many people liked the swag we had on offer!

Release of 1.22.0 and 1.22.1
The 1.22.0 release improved ingestion performance by upto 40% through the introduction of pipelining and by taking advantage of RocksDB-specific functionality. It also included several dependency upgrades and improved the native experience for our users developing on Apple hardware (where previously LMDB and Kafka were lacking M1 support).
Delivering the ingestion performance improvements involved a few interesting technical changes:
-
Moving to a pipelined ingestion model where work is able to happen across multiple threads, and document requests can be batched up across transactions
-
Pushing down in-transaction speculative writes to RocksDB’s
WriteBatchWithIndexAPI -
Making use of RocksDB’s Column Families for storing different parts of the index keyspace separately
In our own testing this work improved bulk ingestion by as much as 40% (e.g. a 10 hour import job is now 6 hours), and the benefit is also experienced during re-indexing (e.g. when upgrading from 1.21.0 to 1.22.1).
1.22.1 was a non-breaking patch release containing a few fixes and also introduced a new pair of built-in query functions: get-start-valid-time and get-end-valid-time.
These are useful to lookup the start/end valid time values of the current entity version during a regular point-in-time Datalog query.
1.22.2-rc1 …available now!
Off the back of the initial pipelining and Column Family work a subsequent round of optimizations was made possible and substantial PR landed last week. Due to the nature of these changes we want to wait for more usage feedback before rolling out the next stable release and therefore will welcome independent evaluation of this Release Candidate. In particular we want to hear about any possible regressions in performance (or bugs!), but positive feedback is appreciated too 🙏
We have measured a wide range of improvements from these changes however the actual speedup is very dependent on the workload.
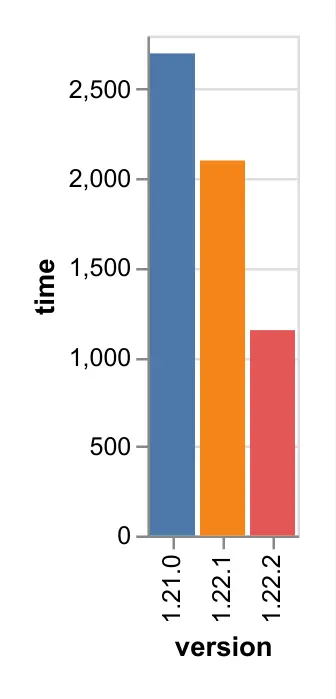
What to expect:
-
Maximum write throughput increased, lower overhead indexer, better multi-core utilization
-
Workload dependent, logs with smaller transactions (e.g. less than 32 docs) will see a much bigger jump
-
Whilst the changes are broadly focused on RocksDB indexes, some of the changes will influence some LDMB workloads
-
There’s a non-zero chance that your deployment is bottlenecked elsewhere so it’s always best to expect a small improvement and be pleasantly surprised if the speedups are greater
-
Testing has shown we still have room between this release and peak theoretical indexing performance with RocksDB (whilst keeping index structure the same)
Let’s review the 3 biggest contributors…
Prefix Seek support on the bitemporal index
As the database grows, an increasing—although ideally sub-linear—amount of time is spent looking up previous entity history keys prior to writing new entries. In many cases however the typical entity being put is completely new and its ID has never been seen before, and therefore no history will be found.
The implication of this is that the I/O costs are essentially wasted when no actual data is retrieved.
Fortunately in these scenarios the I/O work can be readily minimized by using a bloom filter (or equivalent) to probabilistically detect 'new' IDs and avoid a significant proportion of unnecessary lookups.
RocksDB itself can provide filtering on key prefixes using its own implementation of bloom filters that are maintained and stored immutably alongside the raw SST data. By default, XT now configures the bitemporal index Column Family to build prefix bloom filters, and conditionally uses them during history lookups. The biggest tradeoff of using these bloom filters is that they can put more pressure on the RocksDB block cache.
Prefix filtering can be enabled using the new option :enable-filters? true on the Rocks configuration. Existing SST files do not get re-written automatically once this option is enabled, but filters will be created whenever new SST files are generated through regular compaction and ongoing writes. A full re-index with this filter option enabled will demonstrate the effect straight away.
It is possible that a similar application of Prefix Seeks could also be used with the other XT indexes to improve general query performance, but for now this remains an area for future investigation.
Buffering of statistics processing
Previously statistics were calculated and written per transaction. For large enough transactions this imposes little overhead, but with very small transactions the cost of computing and writing the 'stats' to the KV store can equate to significant CPU time.
Instead, these stats are now computed and written only after either (a) 32 documents are written OR (b) 500ms elapses. The impact of this buffering varies depending on batch size, and the difference is most significant when transactions contain few documents.
In the extreme case, where there is a single put operation per transaction, a ~3.5x speedup has been observed:
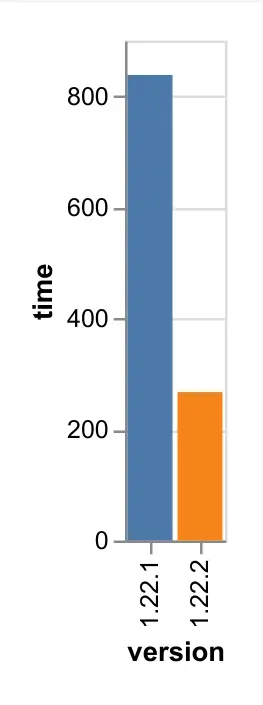
Increased # of RocksDB background jobs
By default Rocks permits 2 background jobs for compaction and flushing.
Following the other improvements write stalls were being observed due to high numbers of 'L0' SST files. To reduce write stalling more potential CPU resources are now allocated for compaction (and flushing to disk) by increasing the maximum number of Rocks background jobs to n-1 CPUs. This change will increase the CPU load on systems whose write throughput requirements are very high.
AuctionMark Transactional Benchmarking
XT has always been developed hand-in-hand with benchmarking suites like TPC-H and WatDiv, however these suites have primarily been used to evaluate complex analytical workloads on static indexes following a single bulk data import (i.e. Online Analytics Processing / OLAP).
AuctionMark is an existing Online Transaction Processing (OLTP) workload benchmark that we have been implementing to help understand the ingestion performance changes. It is hoped that AuctionMark will be an effective tool to provide us with new insights into future tuning and performance optimizations, particularly as we look ahead to near-term work on cache tuning and memory handling.
To aid the development experience of using AuctionMark we have been producing detailed visual reports to draw comparisons across independent configuration runs:
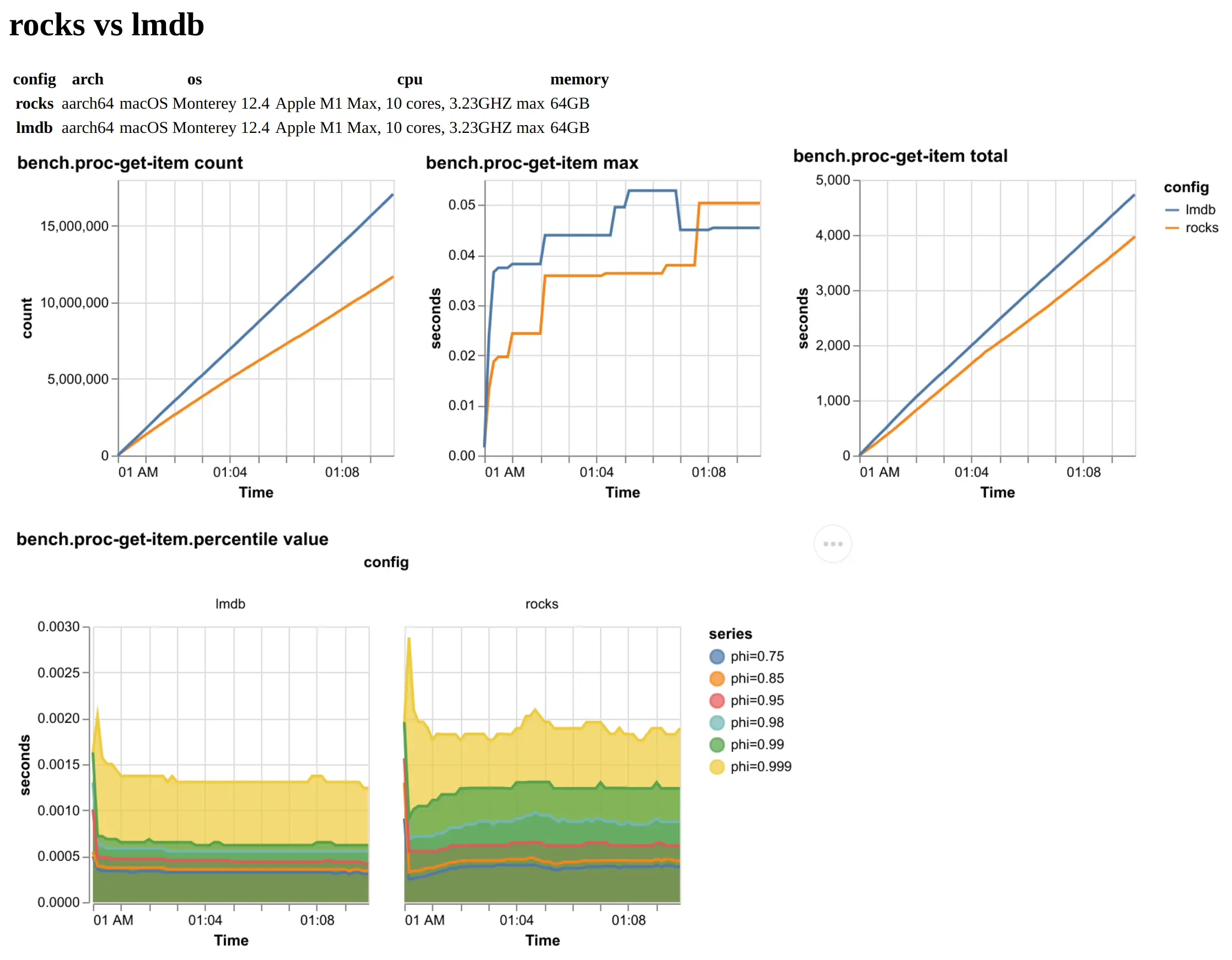
Community
It’s always great to see interesting things being worked on:
-
xtdberl — Erlang/OTP interface that can send queries and documents to XT using Jinterface (which makes XT appear like an Erlang process)
-
"Datalog for JSON munging" — a Clerk notebook that showcases a few tricks for working with JSON:API data
-
Biff — a batteries-included Clojure web framework that has been going for a while now and is a great starting point for anyone who is curious to see how XT can be used alongside other powerful Clojure-based technologies like Malli
Barring that, drop us a line at hello@xtdb.com 👋


