Thursday, 27 April, 2023
Announcing XTDB 2.x Early Access
 Jeremy Taylor
Jeremy Taylor We’re delighted to announce that XTDB 2.x Early Access is now available! This means pre-alpha release artifacts are available for anyone to easily kick the tyres, along with an initial (unstable) API. Visit the 2.x Early Access page for the very latest information and pointers on how you can easily give 2.x a spin right now.
For those unaware, Clojure/conj 2023 is the premier Clojure conference being held today and tomorrow in Durham, NC, and it marks an exciting milestone as the launch event for this 2.x Early Access phase of development. Jon Pither, CEO, is imminently giving a talk on the "State of XTDB" (streaming live, and recording available soon! EDIT: now available) where he will outline our thinking and plans for the long-awaited upcoming major 2.x release of XTDB.
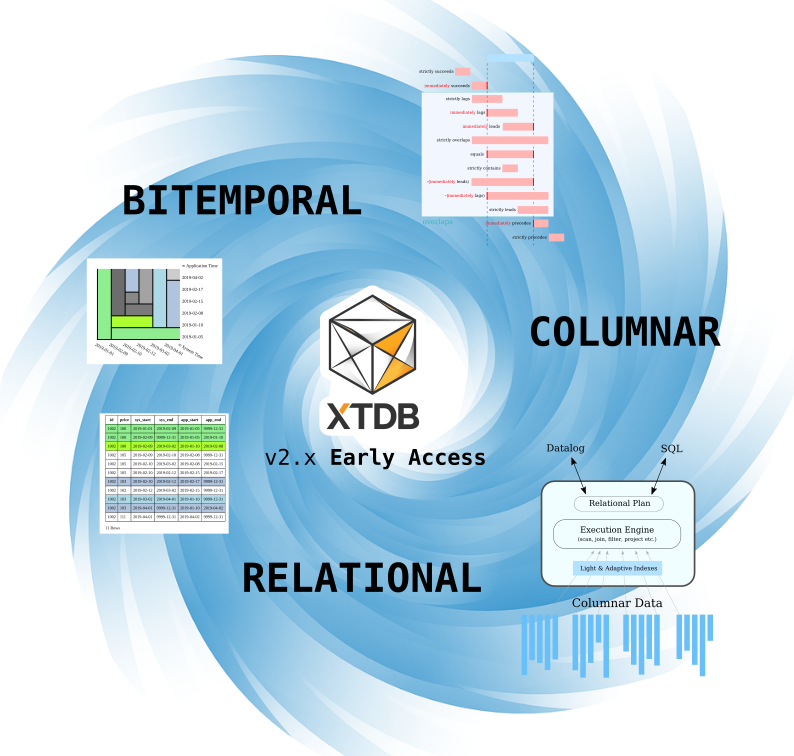
The major highlights of 2.x are:
-
Full bitemporality - where XTDB has previously been optimized for point-in-time historical queries, 2.x now supports “Cross time” queries, e.g. temporal joins and temporal range scans. This unlocks the complete history of data for rich analysis.
-
Columnar architecture - 2.x implements a columnar data architecture that "separates storage and compute" - this modern, Big-Data-inspired architecture is built around Apache Arrow and commodity object storage. Most importantly, this design reduces operational costs when retaining large volumes of historical data.
-
Dynamic relational engine - 2.x embraces the concept of 'tables'. Unlike typical SQL tables with row-oriented storage, these XTDB columnar tables are always 'sparse' (storing NULLs is cheap) and 'wide' (storing lots of columns is fine). Tables allow for natural partitioning of data to provide better performance, support introspection, and enable XTDB to provide a SQL interface as a first-class citizen alongside an enhanced version of Datalog. 2.x supports arbitrarily nested data as well, meaning no upfront schema needs to be specified before records can be inserted. Complex and nested data is automatically represented using Apache Arrow types.
There is plenty of hard work still to be done during this period of Early Access, but we are keen to develop in public and bring everyone on the journey with us. Therefore, please do join the community discussion about this news over on discuss.xtdb.com where we will be happy to answer your questions, or send us an email. We would love to hear what you think!
In other news, a new stable release of XTDB just dropped today as well, see 1.23.2 - huge thanks to everyone who helped with that 🙌
