
A state-owned energy retailer is the sole market participant in one of the world's largest isolated electricity networks. With a significant proportion of households now generating solar power, the company set out to build a Virtual Power Plant (VPP) platform, aggregating customer-owned solar panels and batteries into a coordinated fleet that could be dispatched as a single grid resource. The platform operates simultaneously as a retailer, VPP operator, and market aggregator, earning revenue for availability and dispatch and sharing those incentives with participating customers.
The core technical challenge was one of time. A VPP is quite unlike a conventional power station: assets are virtual, customers opt in and out, schedules are sent ahead of time and then corrected, OEM telemetry arrives late or out of sequence, and billing can lag behind operational reality. The regulatory compliance mandate required an auditable record of exactly why every dispatch decision was made at the precise moment it was made. Not an approximation, not a reconstruction from logs. The system needed to distinguish between what the platform knew at decision time and what was later corrected.
"The energy market is essentially a bitemporal model. Just not acknowledged."
The team had already explored Kafka-based event sourcing before reaching out to XTDB. The bitemporal data model was the fit they needed: valid time for forward-looking schedules (what should happen and when), and system time for a complete, immutable audit trail of when the company knew what, even as corrections arrive after the fact. XTDB became the "bitemporal historian" for the platform, replacing both the expensive per-tag historian model common in the energy industry and the custom Python reconciliation logic they'd been building around it.
"We purposefully didn't over-engineer the application stack. We wanted the data to speak for itself. As emerging requirements came in, whether compliance obligations or new market rules, we needed to iterate quickly. And SQL was a natural fit."
The team deliberately kept the application layer thin and data-centric, using XTDB's standard SQL interface so they could iterate fast as regulatory requirements evolved in parallel with the build. BI tooling connects directly over SQL, so analysts across customer, billing, and market-operations teams can query a consistent data model without having to care about the temporal plumbing underneath.
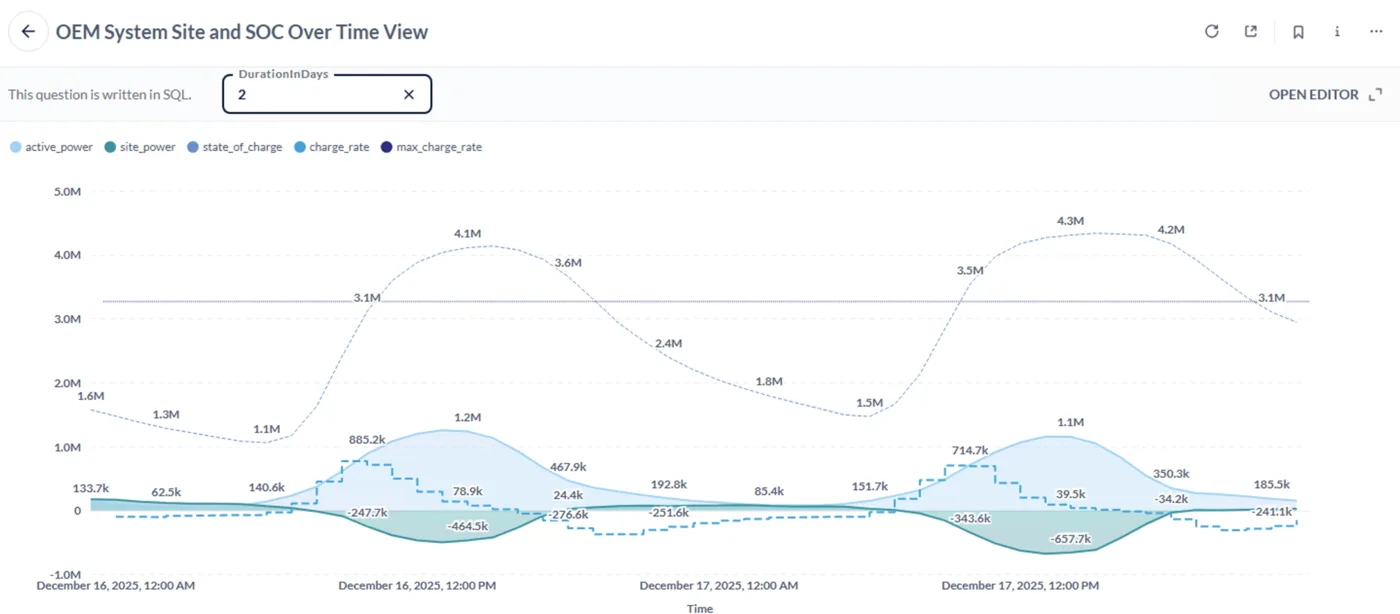
The platform is live and producing measurable grid impact. XTDB's native interval algebra and bitemporal binning logic correctly handles late or overlapping telemetry from OEM devices, which otherwise causes systematic overcompensation in a conventional moving-average database (a real pain point in the energy industry). Forecasts produced by the data science team are stored back into XTDB as valid-time intervals, so the same query interface serves both historical reconciliation and forward-looking scheduling.
EVs alone are expected to significantly increase the device count. The platform's data backbone will need to support price-responsive signalling, sub-five-minute market participation, and expanded service types, all of which compound the bitemporal complexity that XTDB was chosen to handle.